The Pattern in One Paragraph
A Semantic Sidecar is a governed semantic layer that sits beside your existing data platforms (databases, lakehouses, BI tools, ML pipelines) and exposes business concepts (dimensions, measures, metrics, business rules) through a unified API. Instead of embedding semantics inside one BI tool or rewriting your stack around a centralized semantic platform, the sidecar pattern lets the same governed model serve AI agents via MCP, analytics workflows via REST, DB-API, or the PostgreSQL Wire Protocol, and reporting via Apache Arrow Flight SQL. The data stays where it is. The semantics live next to it, version-controlled, and addressable by anyone who needs them.
One sentence: the Semantic Sidecar pattern decouples business semantics from any single consumer, so AI agents, analytics, and data systems all query the same governed truth without architectural lock-in.
The Problem It Solves
Most organizations land in one of two failure modes around business semantics:
- Embedded-in-BI: the semantic model lives inside Tableau, Power BI, Looker, or another BI tool. Only that tool benefits. Your AI agents, data science notebooks, and ML pipelines all reinvent the same definitions, drift apart, and produce conflicting numbers.
- Centralized-rewrite: a "modern semantic layer" platform demands you route all queries through it, often with its own query engine, its own auth model, and its own SaaS billing. The architecture change is huge, and you still end up with vendor lock-in.
The Semantic Sidecar pattern is the third option. It treats semantics as a shared service that any consumer can call, without forcing anyone to change how they store or process data.
Sidecar vs Embedded vs Centralized
| Aspect | Embedded (in BI) | Centralized platform | Semantic Sidecar |
|---|---|---|---|
| Architecture change | None | Major | None |
| Consumer scope | One BI tool | Anything routed through it | Any consumer (AI, BI, ML, API) |
| AI agent access | No | Sometimes (via plugin) | First-class (MCP, REST) |
| Version control | Tool-specific | Tool-specific | YAML in git |
| Vendor lock-in | High | High | Low (open source) |
| Where SQL is generated | BI tool | Centralized engine | Sidecar (custom AST) |
How OrionBelt Implements the Semantic Sidecar
OrionBelt Semantic Layer (OBSL) is an open-source reference implementation of the Semantic Sidecar pattern. It is API-first and consumer-agnostic by design.
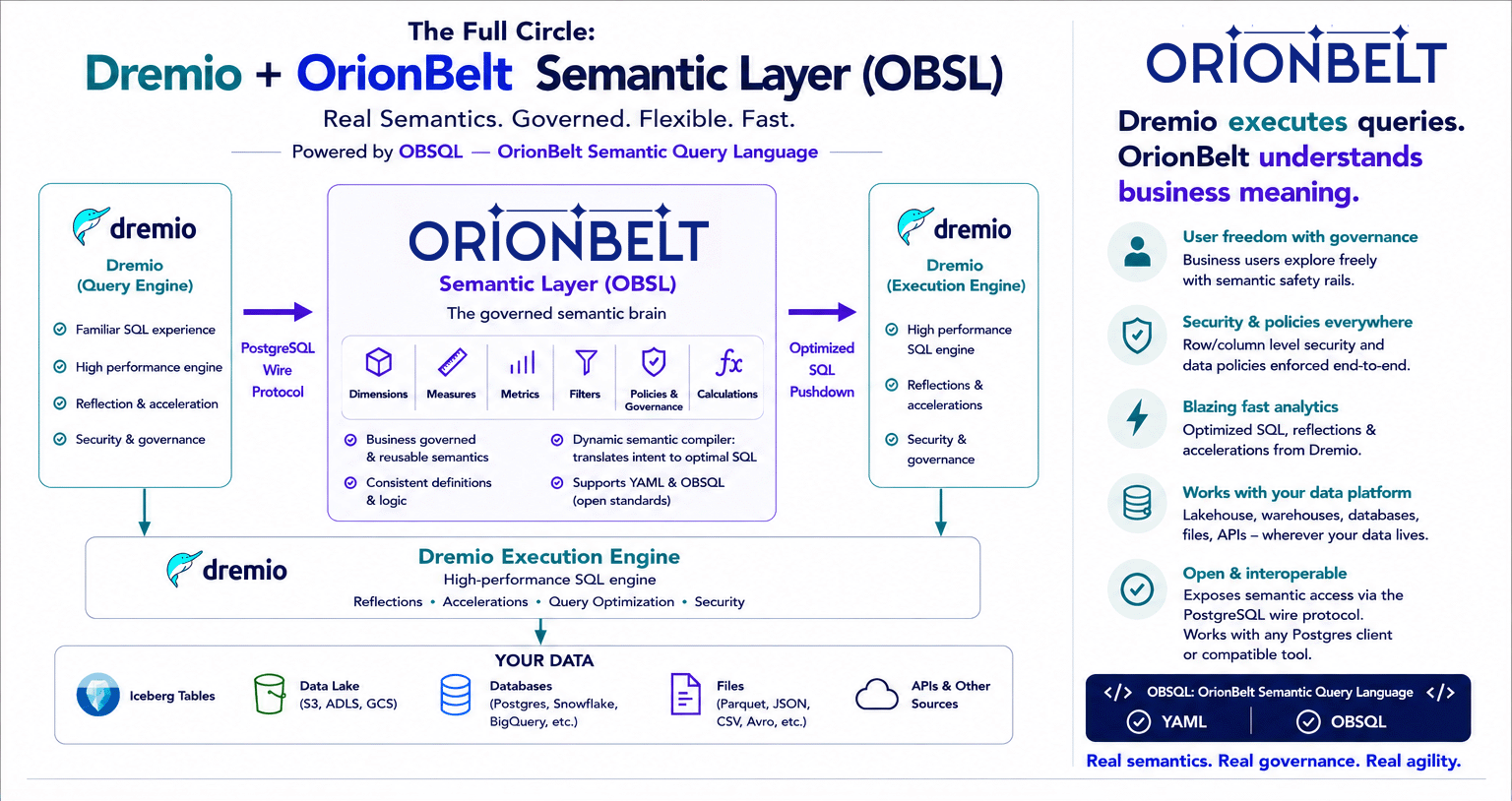
The model: declarative YAML (OBML)
You define dimensions, measures, metrics, business rules, joins, and semantic context in .obml.yaml files. These live in git, get reviewed in pull requests, and are versioned alongside the rest of your code. There is no proprietary modeling UI to learn and no SaaS lock-in.
The engine: a custom SQL AST
OBSL compiles your YAML model into an internal SQL Abstract Syntax Tree, then emits dialect-specific SQL for PostgreSQL, Snowflake, BigQuery, ClickHouse, Databricks, DuckDB/MotherDuck, Dremio, and MySQL. Because the AST is custom (not string templating), the output is guaranteed to be syntactically valid and injection-safe.
Fan-trap prevention via CFL
Multi-fact queries spanning independent fact tables produce silent over-counting in naive SQL generation (the classic "fan trap"). OBSL's Composite Fact Layer (CFL) detects multi-fact queries, splits them, runs them independently, and combines via UNION ALL. AI agents and BI tools get correct numbers by construction.
The unified API surface
- REST API with OpenAPI docs (FastAPI)
- MCP Server for Agentic AI consumers (Claude, ChatGPT, Copilot, Cursor, Windsurf)
- PostgreSQL Wire Protocol endpoint: any
psql, JDBC, ODBC, or BI client can connect to OBSL as if it were a Postgres database - Gradio UI for interactive exploration
- DB-API 2.0 + Apache Arrow Flight SQL drivers for analytics tools and notebooks
- OBSL Graph + SPARQL 1.1 for semantic queries over the model itself
- OSI interoperability: bidirectional with Open Semantic Interchange
When to Use a Semantic Sidecar
The Semantic Sidecar pattern is the right call when:
- You already have data platforms (warehouses, lakehouses, BI tools) and don't want to rewrite them.
- AI agents need governed data access via MCP, not raw SQL with hallucination risk.
- Multiple consumers (BI dashboards, AI assistants, scheduled reports, ML training pipelines) need consistent metric definitions.
- You want analytics defined as version-controlled code, reviewed in pull requests, deployable through CI.
- You need regulatory or business KPIs computed the same way every time, with full audit trail.
Related Concepts
The Semantic Sidecar pattern intersects with several adjacent ideas:
- Analytics as Code: semantics in version control, compiled to executable artifacts.
- Headless BI: similar separation of model from presentation, but typically still tied to a query engine.
- Metric stores / Metric layers: a narrower subset, usually metrics only without dimensions, joins, or business rules.
- Knowledge graphs / Ontologies: complementary. A Semantic Sidecar can be backed by an ontology (as OBSL is) for richer semantic discovery.
Frequently Asked Questions
What is a Semantic Sidecar?
A governed semantic layer that runs alongside your existing data platforms instead of inside a BI tool or as a centralized rewrite. It injects business semantics into AI agents, analytics workflows, and data systems through a unified API, with no architecture change.
How does a Semantic Sidecar differ from an embedded semantic layer?
An embedded semantic layer lives inside a single BI tool and only that tool can use it. A Semantic Sidecar is platform-agnostic: the same governed model serves AI agents via MCP, analytics workflows via REST, DB-API, or PostgreSQL Wire Protocol, and reporting via Apache Arrow Flight SQL. One model, many consumers, no vendor lock-in.
Why do AI agents need a Semantic Sidecar?
LLMs hallucinate SQL, pick wrong joins, and produce inconsistent metrics when given raw database schemas. A Semantic Sidecar gives them governed business concepts to query instead. The agent asks for "revenue by region last quarter" and the sidecar compiles deterministic, fan-trap-free SQL against the right tables.
How does OrionBelt implement the Semantic Sidecar pattern?
OBSL compiles declarative YAML models (OBML) into optimized SQL across 8 database dialects via a custom AST. It exposes the same governed semantics through a REST API, MCP server, Gradio UI, DB-API 2.0, Apache Arrow Flight SQL, and a PostgreSQL Wire Protocol endpoint (any psql, JDBC, ODBC, or BI client connects as if to a Postgres database). Agents and analytics tools query in business concepts; OBSL handles SQL generation, fan-trap prevention, freshness-aware caching, and audit logging.
When should I use a Semantic Sidecar instead of a traditional semantic layer?
Choose the Semantic Sidecar pattern when you already have data platforms in place and don't want to rewrite them, when AI agents need governed data access (not raw SQL), when multiple consumers (BI, agents, reports, ML pipelines) need consistent metrics, or when you want analytics defined as version-controlled code.